Qevlar AI

How organizational context closes the learning loop, so every investigation makes the next one sharper.

Your best analyst quit last month. Everything they knew about your environment walked out with them.
They knew the finance host that fires alerts every Tuesday is just a backup job. They knew the service account that signs in at 2am is expected. It lived in their head, in a Slack thread, in a ticket comment no one will ever open again.
So the next analyst starts from zero. The same alert gets investigated for the fifth time. The loop never closes, and the SOC never gets smarter.
This is institutional amnesia. It is the quiet tax on every SOC, and it is exactly what Qevlar was built to prevent. We turn every investigation your team runs into context the SOC keeps, validates, and builds on. The result is a SOC that learns instead of forgetting, and gets sharper with every case it closes.
Most AI SOC platforms get partway here. They let you write organizational context by hand, then leave it to decay. But writing context was never the hard part. Keeping it correct, current, and trusted is the work. That is the loop, and closing it is the whole point.
Here is how Qevlar closes it.
Manual context is always a step behind a moving environment. So Qevlar does the watching for you. It reads across hundreds of closed investigations, finds the behaviors that keep resolving the same way, and drafts them as context for review. The scanning no analyst has time for happens on its own. Nothing goes active without a human yes, but the discovery is automatic. Your knowledge base starts building itself from work you have already done.
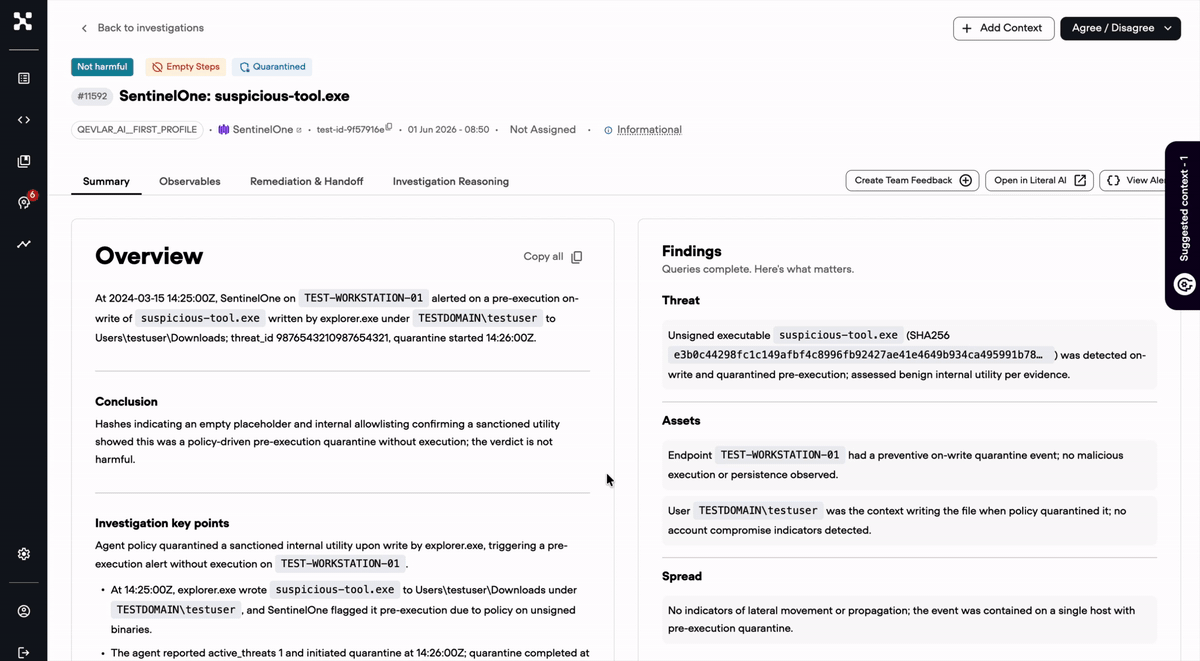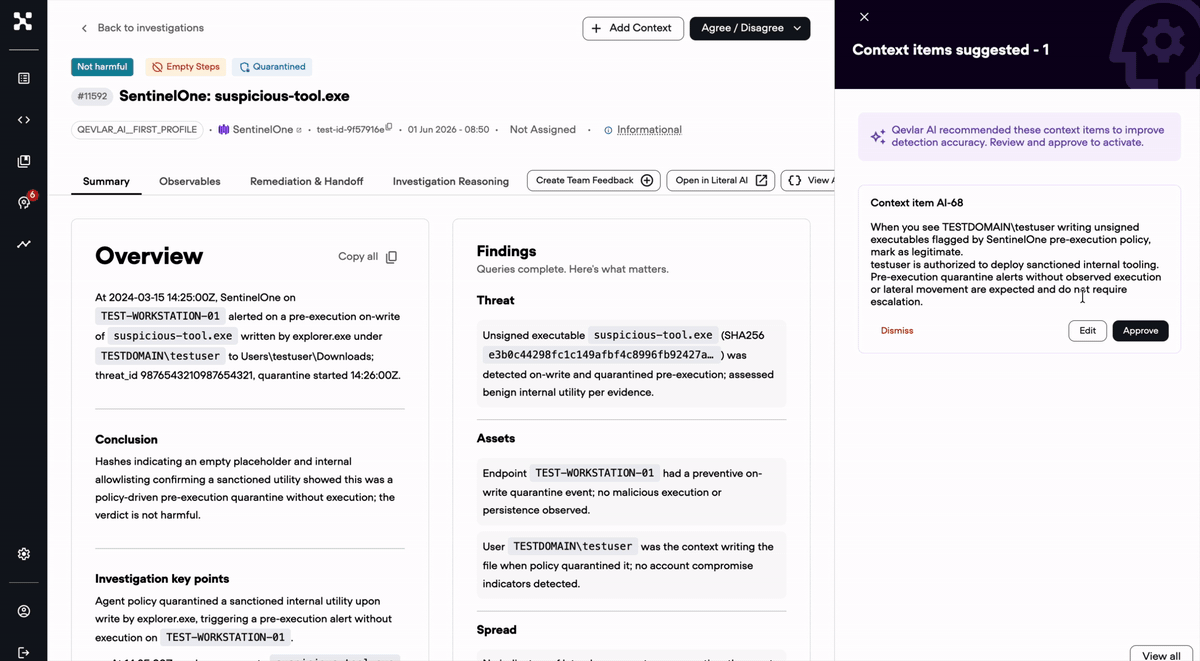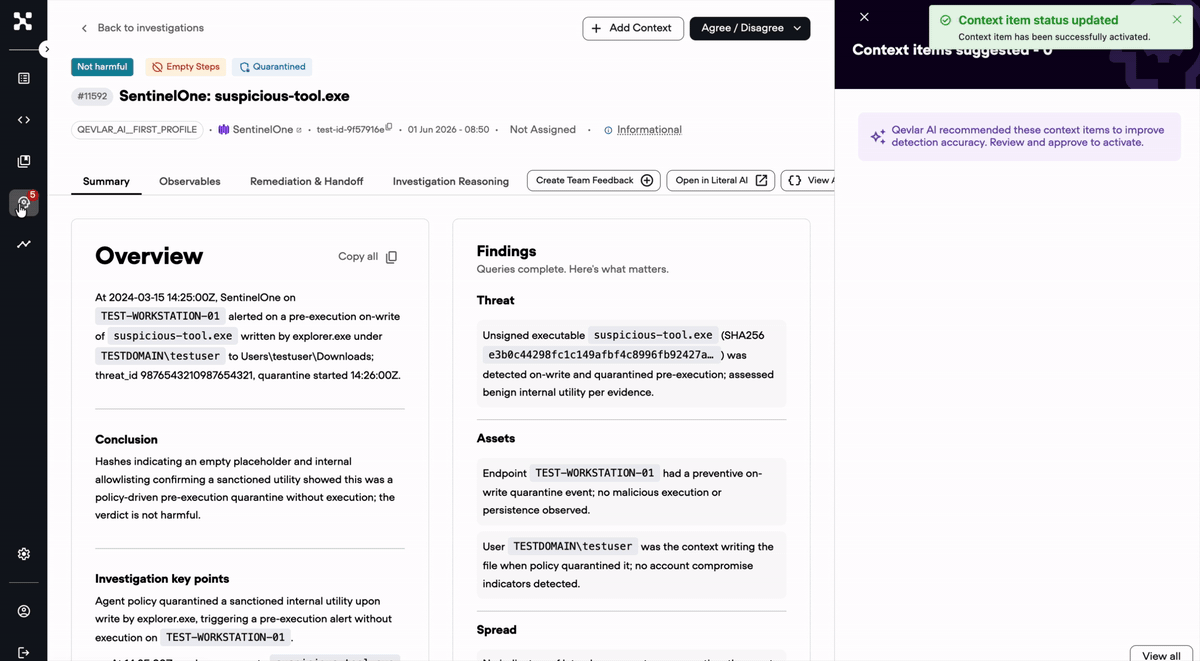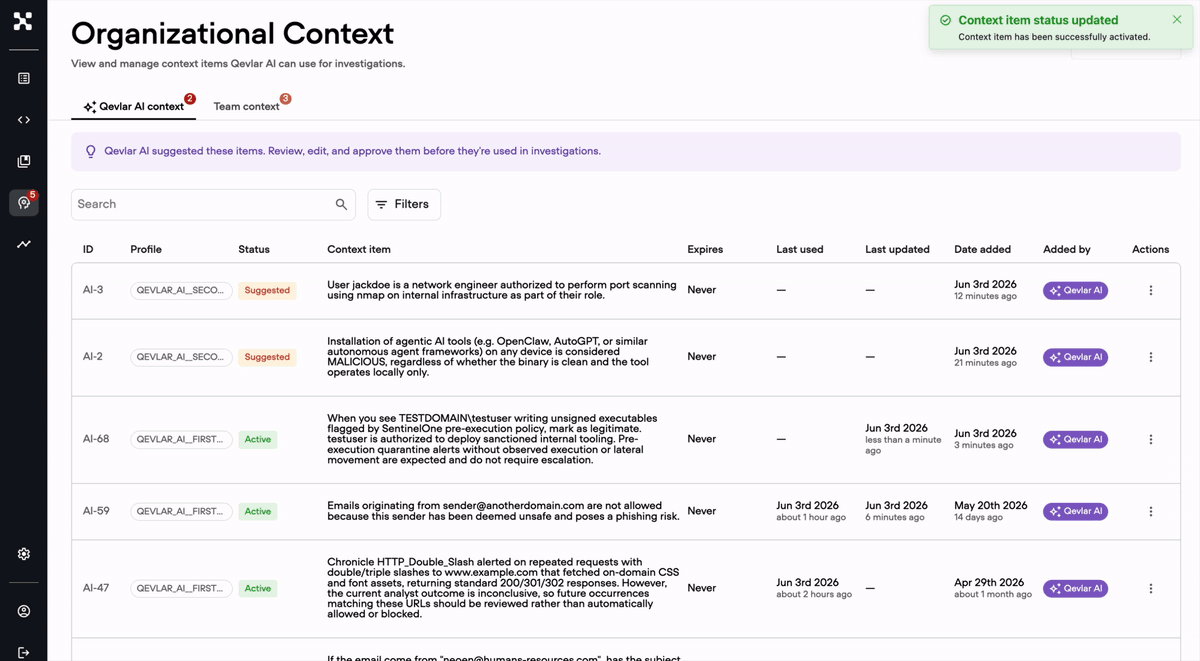
Every time an analyst disagrees with a verdict, they are telling you something true about your environment. Today that signal dies in a comment box. With Qevlar, disagreement starts a loop.
The analyst explains the call in one sentence. Qevlar pulls out the observables, the reasoning, and the verdict implication, then writes it back as structured context and saves it in the Organizational Context. Every future investigation that touches the same host, user, or process inherits it automatically. The judgment does not evaporate. It goes to work.
.gif)
The instinct to add context is right. The risk is context that changes more than you meant it to. So before anything goes live, Qevlar replays it against your recent alerts and shows you exactly how verdicts would have shifted. You see what it fixes. You see anything it touches that you did not intend. Then you decide. Trust in AI was never binary. The real question is whether you can see enough to know when to trust it, and the impact preview answers that before a single live investigation is affected.
.gif)
For the builders: Qevlar matches recent alerts to the observables tied to the new context, replays them through the full investigation pipeline, and returns a per alert verdict diff with the reasoning behind each change.
Nothing reaches a live verdict on one person's say so. When an analyst submits a context item, an admin reviews it, edits it if needed, and approves it. The knowledge base your AI runs on reflects deliberate calls by the people who own your security posture.
This is what closing the loop actually buys you. Every investigation generates signal. The more you run, the more the SOC learns. The more it learns, the faster and more precisely it works.
.gif)
A few months in, your AI SOC is not the same one you deployed on day one. The one you have now knows your environment. It knows which users look strange but are fine. It knows which patterns have resolved the same way dozens of times. Cases that used to need a senior analyst now close with confidence, because the judgment behind them was captured, validated, and put to work.
As we wrote in The SOC as the Enabler of a Self Healing Posture, your SOC's real output was never closed tickets. It is a posture that compounds. Organizational context is the engine that gets you there.
See how Qevlar applies your organizational context to every investigation. Book a demo.

It's the loss of SOC knowledge when analysts leave or when context gets buried in tickets, Slack threads, and comments no one reopens. The same alerts get re-investigated and the team never compounds what it learns. Qevlar prevents this by turning every investigation into structured context the SOC keeps and reuses.
When an analyst disagrees with a verdict, Qevlar turns that one-sentence explanation into structured context saved in the Organizational Context layer. It extracts the observables, reasoning, and verdict implication, then applies them automatically to every future investigation touching the same host, user, or process.
It replays the new context against your recent alerts and shows a per-alert verdict diff before anything goes active. You see exactly what it fixes and anything it affects that you did not intend, then decide. Nothing reaches a live verdict without an admin review and approval.
Because every investigation generates signal that compounds into validated context. The AI learns which users look unusual but are safe and which patterns resolve the same way repeatedly. A few months in, cases that once needed a senior analyst close with confidence.


