


Beyond the Prompt: Engineering Trustworthy AI SOC Analysts


The cybersecurity landscape has witnessed a paradigm shift with the advent of Large Language Models. Where AI in security operations was previously constrained to detection, malware analysis, Domain Generation Algorithm (DGA) identification, and basic prioritization tasks, LLMs have expanded the possibilities to include alert enrichment, investigation copilots, automated report generation, and complex reasoning tasks. This expansion has opened new frontiers in security operations, promising to address the chronic shortage of skilled cybersecurity professionals while enhancing the speed and depth of security investigations.
However, this promise comes with significant challenges. In cybersecurity operations, where false positives can lead to alert fatigue and false negatives can result in successful attacks, there is no margin for error. The stochastic nature of LLMs (their tendency to produce different outputs for identical inputs) presents a fundamental challenge to their adoption in security-critical environments.
Empirical Study: Measuring Stochastic Variability
To quantify the extent of stochastic behavior in LLM-based security investigations, Qevlar AI conducted a comprehensive empirical study using real-world security alerts processed by our production systems. Our methodology leveraged Qevlar's operational experience with thousands of enterprise security investigations, providing unprecedented insights into LLM variability in live security environments.
Phase 1: Production Dataset ConstructionWorking with real alerts investigated by Qevlar's autonomous agents in production environments, we identified investigations requiring 3 to 20 steps for resolution. This dataset represents actual threat scenarios encountered across diverse enterprise environments, ensuring our study reflects the complexity and variety of modern cybersecurity operations. For each complexity level, we selected 10 representative alerts, resulting in a curated dataset of 180 anonymized security scenarios that span the full spectrum of contemporary security investigations.
Phase 2: Controlled LLM Agent TestingWe equipped an LLM agent with Qevlar's comprehensive investigation action catalogue, designed through extensive operational experience with enterprise security environments. Each alert was submitted to the agent 100 times, generating 18,000 total investigation attempts. We tracked complete investigation paths (sequences of actions taken to reach conclusions), enabling detailed analysis of consistency patterns across different complexity levels.
Key Definitions
To ensure clarity in our analysis, we established precise terminology:
- Step: A single investigation action performed by the LLM agent
- Path: A complete sequence of steps taken to investigate an alert
- Canonical Path: The most frequently observed investigation sequence for a given alert
- Alternative Path: Any deviation from the canonical path, including added, removed, or modified steps
- Divergence Rate: The percentage of investigations producing alternative paths
Findings: Four Critical Limits of Stochastic Intelligence
Limit 1: Investigation Depth Variability
Our analysis revealed significant inconsistencies in investigation thoroughness. Even for identical alerts, LLM agents demonstrated varying levels of investigative depth. In some instances, agents would skip critical enrichment steps (such as Cyber Threat Intelligence (CTI) queries) while still reaching similar conclusions. This behavior raises concerns about the comprehensiveness and reliability of AI-driven investigations.
For example, analyzing suspicious outbound traffic, the canonical 3-step investigation path appeared in only 75% of cases. Alternative paths, including abbreviated 2-step sequences that omitted CTI enrichment, occurred in 17% of attempts. While these abbreviated investigations sometimes reached correct conclusions, they potentially missed critical context that could influence threat assessment and response prioritization.

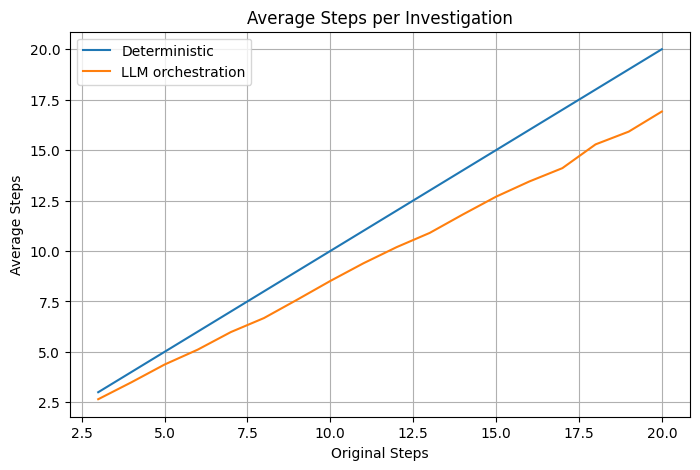
Limit 2: Canonical Path Instability
The concept of a "canonical" investigation path proved more fluid than anticipated. Even the most frequently observed paths for simple alerts rarely exceeded 75% consistency. This instability becomes more pronounced as alert complexity increases, challenging the assumption that AI agents will develop standard operating procedures analogous to human analysts.
The implications for SOC standardization are significant. Organizations typically rely on consistent investigation procedures to ensure comprehensive threat analysis and facilitate knowledge transfer between analysts. When AI agents follow unpredictable paths, it becomes difficult to establish reliable baselines for investigation quality and completeness.
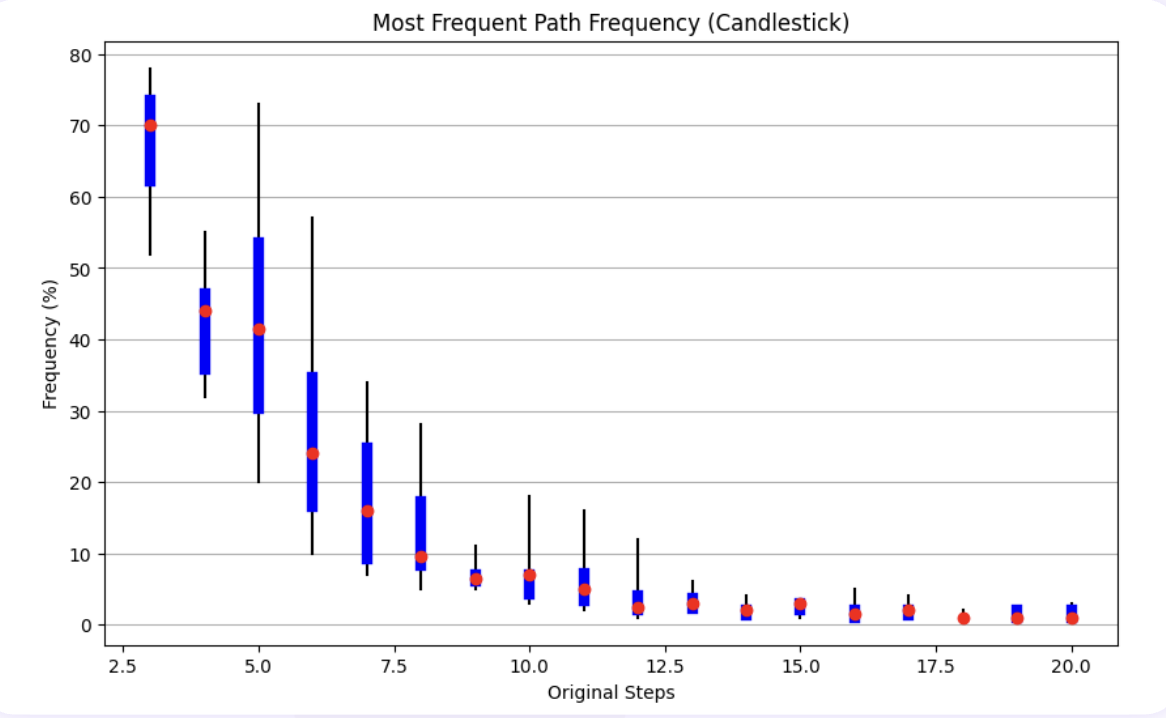
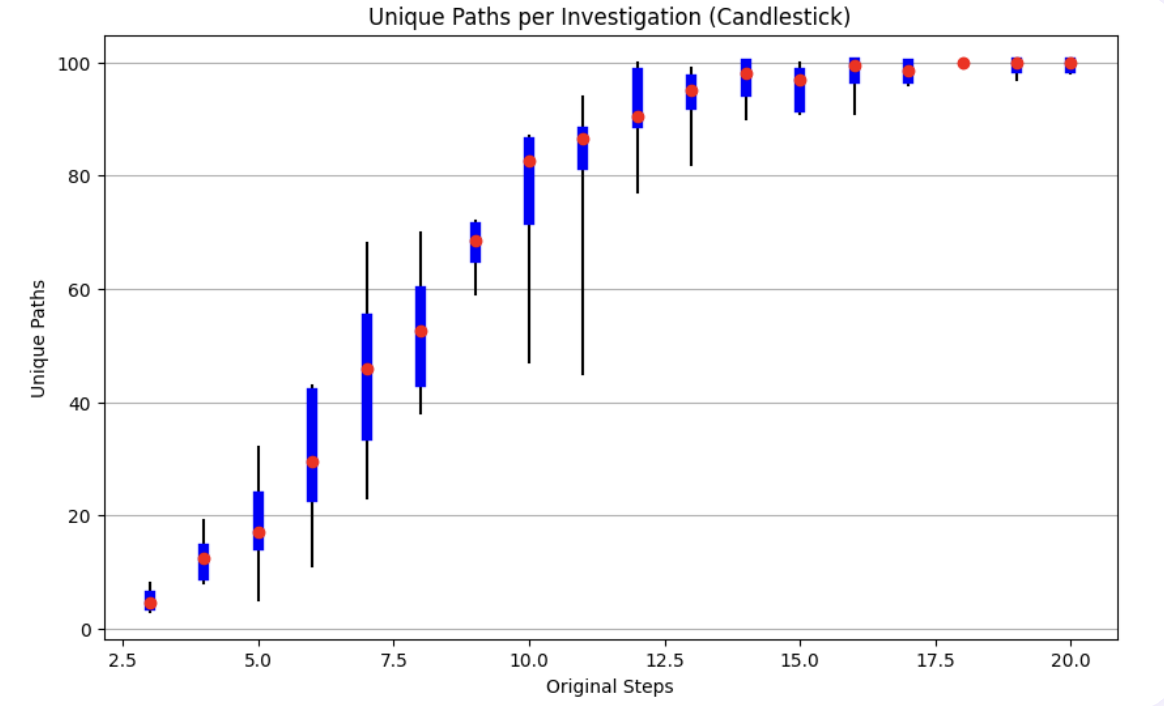
Limit 3: Path Proliferation in Complex Scenarios
Complex investigations demonstrated extreme path variability, with some alerts generating nearly as many unique investigation paths as attempts. In our most complex case study—an email security alert requiring an average of 17.2 steps—we observed 90 distinct paths across 100 attempts. The canonical path represented only 3% of investigations, highlighting the challenge of achieving consistency in sophisticated threat scenarios.
This proliferation of investigation approaches mirrors the complexity of modern cyber threats but presents operational challenges. SOC teams cannot effectively review, validate, or learn from AI investigations when each follows a unique path. The resulting unpredictability undermines confidence in AI-driven analysis and complicates integration with existing security workflows.
Limit 4: Outcome Variability
Beyond orchestration inconsistencies, we observed variations in investigation conclusions and threat assessments. Identical alerts occasionally received different severity ratings or threat classifications, depending on the specific investigation path followed. This outcome variability represents perhaps the most critical limitation, as it directly impacts incident response decisions and resource allocation.

The challenge extends to report generation and communication. Inconsistent conclusions make it difficult to maintain coherent threat intelligence and may lead to conflicting guidance for preventive measures or system modifications.
Building Trustworthy AI SOC Analysts
Architectural Principles for Stability
Based on our findings, we propose several architectural principles for developing reliable AI-powered security operations:
1. Task Decomposition and Specialization
Rather than deploying general-purpose LLM agents, organizations should focus on narrow, well-defined tasks. By constraining the scope of AI decision-making, we can reduce variability and improve predictability. Each LLM component should function as a specialized microservice with clearly defined inputs, outputs, and responsibilities.
2. Structured Output Enforcement
Implementing rigid output formats through JSON schemas and validation rules helps constrain LLM variability. By demanding structured responses rather than free-form analysis, we can ensure consistency in how information is processed and presented to security teams.
3. Chain Architecture with Validation
Breaking complex investigations into sequential stages with validation checkpoints between each phase helps maintain consistency and enables error detection. Each stage can employ specialized prompts optimized for specific tasks, reducing the cognitive load on individual LLM calls.
4. Self-Correction Mechanisms
Implementing loops where LLMs validate their own outputs against consistency rules can help identify and correct deviations from expected patterns. These mechanisms should include automatic retry capabilities with refined prompts when inconsistencies are detected.
The Qevlar Solution: Graph-AI Engine Ensures Consistency
Recognizing these fundamental limitations, Qevlar AI has adopted a new approach that addresses the stochastic challenges while preserving the analytical power of LLMs. Our graph orchestration architecture, battle-tested in enterprise production environments, represents the evolution beyond traditional AI approaches.
Graph-Based Investigation OrchestrationAt the core of Qevlar's innovation is our proprietary graph orchestration system. Unlike pure LLM approaches that suffer from path variability, Qevlar's deterministic graph structure defines investigation workflows with mathematical precision. Each investigation step is associated to a priority based on alert characteristics, threat intelligence, and historical effectiveness data. This approach eliminates the random path selection that plagues traditional LLM agents while maintaining the adaptability required for sophisticated threat analysis.
Multi-Stage Intelligence ProcessingQevlar's system breaks complex investigations into discrete stages, each optimized for specific analytical tasks:
- Email Content Analysis: Specialized processing of phishing and malicious communication attempts
- Device Behavior Analysis: Comprehensive endpoint activity correlation and anomaly detection
- File Sandboxing Integration: Automated malware analysis and threat classification
- Log Extraction and Correlation: Multi-source data aggregation and timeline reconstruction
Each stage employs purpose-built LLM calls with defined inputs and outputs, ensuring consistency while maximizing analytical depth.
Validation and Quality AssuranceQevlar's architecture includes comprehensive validation mechanisms at every processing stage. Output parsing with JSON Schema validation, explicit business rule checking, and automatic fallback to classical methods ensure that our autonomous agents maintain reliability even when facing novel or complex scenarios.
Production-Proven ResultsIn production environments, Qevlar's hybrid approach delivers:
- Consistent Analysis: Deterministic investigation paths ensure reproducible results
- Rapid Processing: <3-minute investigation times that rival pure LLM speed
- Enterprise Reliability: Production-grade stability suitable for critical security operations
- Immediate Deployment: Ready-to-use autonomous agents requiring minimal configuration
The result is a concise, actionable report delivered through Qevlar's intuitive interface, providing security teams with the comprehensive analysis they need while maintaining the consistency and reliability that enterprise security demands.
With Qevlar AI, we’ve achieved the depth and consistency of investigation we’ve always aimed for. Every alert, no matter how subtle, is analyzed and documented in minutes. It has given us confidence, clarity, and the ability to scale without compromise.
Daniel Aldstam, Chief Security Officer, GlobalConnect
With Qevlar AI, our SOC analysts are now “augmented analysts”, capable of accelerating response times while maintaining quality. This partnership equips us to better protect our clients against evolving cyber threats.”
Eric Bohec, CTO, Nomios
Conclusion
Organizations that successfully navigate the AI transformation in cybersecurity will be those that choose proven solutions over experimental approaches. Qevlar's graph-ML orchestration represents the culmination of extensive research, development, and real-world validation, delivering the promise of AI-powered security operations without the risks associated with stochastic intelligence.
Subscribe to our newsletter
Get started with our pilot program. See results immediately



